
PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第29讲:执行计划与成本估算
内容1 : PostgreSQL中查询执行流程
内容2 : 全表扫描成本估算
内容3 : 索引扫描成本估算
概述
· SQL语句执行五步骤

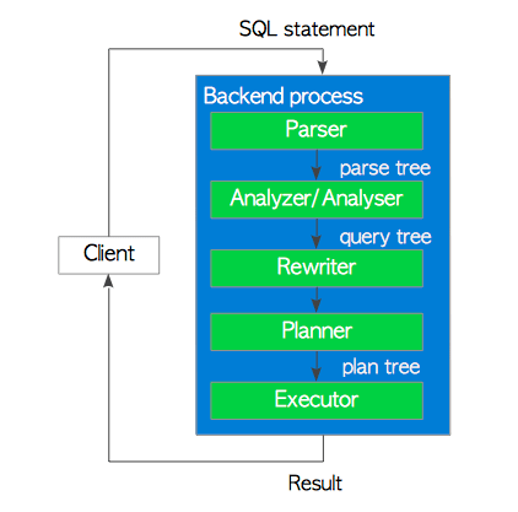
Parser
解析器生成一个解析树,后续子系统可以从纯文本的SQL语句中读取该树。
Analyzer/Analyser
分析器/对解析器生成的解析树运行语义分析,并生成查询树。
Rewriter
重写器是实现规则系统的系统,必要时根据pg_rules系统目录中存储的规则转换查询树。
PostgreSQL中的视图是通过规则系统实现的。通过“创建视图”命令定义视图时,将自动生成相应的规则并将其存储在目录中。
假设已经定义了以下视图并且相应的规则存储在pg_rules系统目录中。
CREATE VIEW employees_list
AS SELECT e.id, e.name, d.name AS department
FROM employees AS e, departments AS d
WHERE e.department_id = d.id;
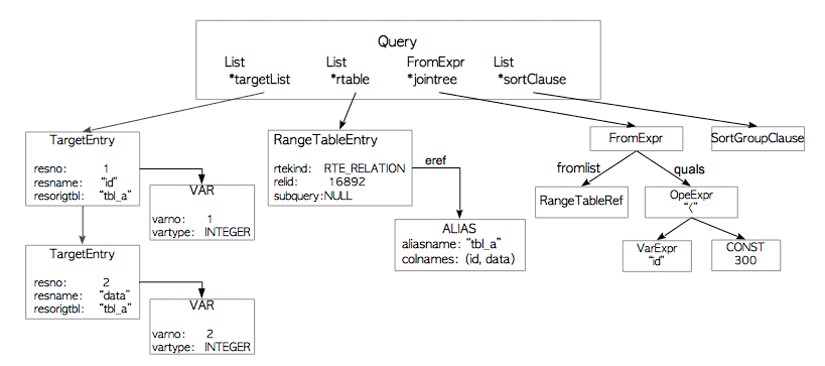
Planner and Executor
规划器从重写器接收查询树,并生成(查询)计划树,执行者可以最有效地处理该树。
pg_hint_plan插件
PostgreSQL不支持SQL中的计划器提示,并且永远不会支持它。如果要在查询中使用提示,需要引用pg_hint_plan扩展插件。
执行计划
· Explain显示sql执行计划
与其他RDBMS一样,PostgreSQL中的explan命令显示计划树本身。
例如:
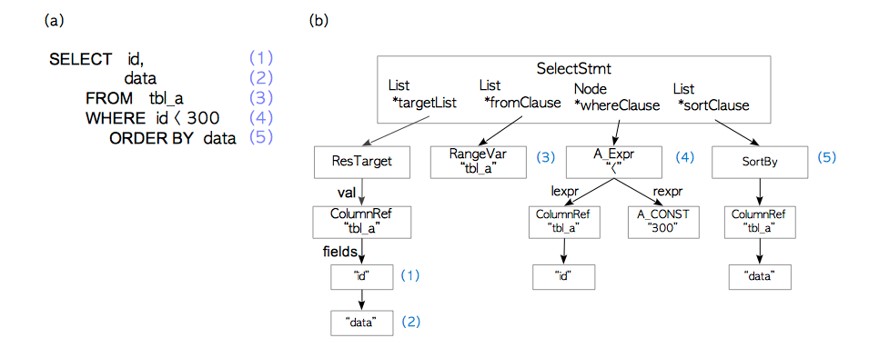
testdb=# EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)
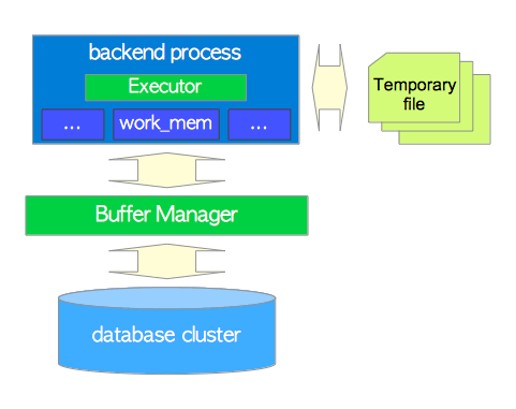
执行器与缓冲区关系
执行器、缓冲区管理器和临时文件之间的关系
单表查询成本估算
· 单表查询中的成本估算
优化基于成本。成本是无量纲值,这些不是绝对的绩效指标,而是比较运营相对绩效的指标。
执行者执行的所有操作都具有相应的成本函数。
三种成本:启动、运行和总计。总成本是启动和运行成本的总和
启动成本是在获取第一个行之前花费的成本。例如,索引扫描节点的启动成本是读取索引页面以访问目标表中的第一个元组的成本。
运行成本是获取所有行的成本。
总成本是启动和运行成本的成本之和。
· 单表查询中的成本估算
EXPLAN命令显示每个操作中的启动和总成本。最简单的例子如下所示:
testdb=# EXPLAIN SELECT * FROM tbl;
QUERY PLAN
---------------------------------------------------------
Seq Scan on tbl (cost=0.00..145.00 rows=10000 width=8)
在第4行中,命令显示有关顺序扫描的信息。在“成本”部分中,有两个值:0.00和145.00。在这种情况下,启动和总成本分别为0.00和145.00。
单表查询成本估算之顺序扫描
· Sequential Scan成本计算
顺序扫描的成本由cost_seqscan()函数估算。我们将探讨如何估算以下查询的顺序扫描成本。
testdb=# SELECT * FROM tbl WHERE id < 8000;
在顺序扫描中,启动成本等于0,运行成本由以下等式定义:
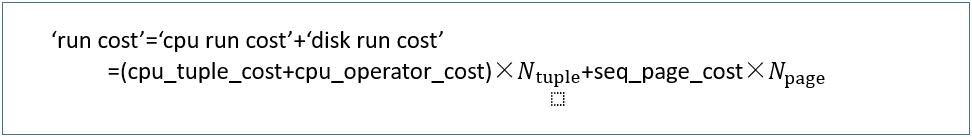
· Sequential Scan成本计算
查询表的块数(page)和行数(tuple):

根据(1,2)得出
‘run cost’=(0.01+0.0025)×10000+1.0×45=170.0
总成本:
‘total cost’=0.0+170.0=170
· Index Scan成本估算
计算下面的查询语句通过索引访问成本计算:
testdb=# SELECT id, data FROM tbl WHERE data < 240;
先查询索引的行数和页数N_(index,tuple) N_(index,page)

· IndexScan 成本估算
启动成本计算公式
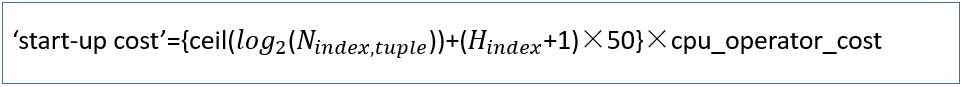
H_index指的是索引的高度
启动成本计算结果:

· IndexScan成本估算
运行成本计算公式
索引扫描的运行成本是表和索引的cpu成本和IO(输入/输出)成本之和
‘run cost’=(‘index cpu cost’+‘table cpu cost’)+(‘index IO cost’+‘table IO cost’)
前三个成本(即索引cpu成本,表cpu成本和索引IO成本)计算公式:

· Selectivity
表的每一列的MCV(Most Common Value)作为一对most_common_vals和most_common_freqs的列存储在pg_stats视图中。
most_common_vals(最常见的的值)是统计MCVs列表的列。
most_common_freqs(最常见值的频率)是统计mcv的频率列。
mydb=# \x
Expanded display is on.
mydb=# SELECT most_common_vals, most_common_freqs
FROM pg_stats
WHERE tablename = 'countries' AND attname='continent';
-[ RECORD 1 ]-----+---------------------------------------------------------------------
most_common_vals | {Africa,Europe,Asia,"North America",Oceania,"South America"}
most_common_freqs | {0.2746114,0.24352331,0.22797927,0.119170986,0.07253886,0.062176164}
· Selectivity
让我们考虑下面的查询,它有一个WHERE子句,“contain=”Asia':
testdb=# SELECT * FROM countries WHERE
continent = 'Asia';
SELECT continent, count(*) AS "number of countries",
(count(*)/(SELECT count(*) FROM countries)::real) AS "number of countries / all countries"
FROM countries GROUP BY continent ORDER BY "number of countries" DESC;
continent | number of countries | number of countries / all countries
---------------+---------------------+-------------------------------------
Africa | 53 | 0.27461139896373055
Europe | 47 | 0.24352331606217617
Asia | 44 | 0.22797927461139897
North America | 23 | 0.11917098445595854
Oceania | 14 | 0.07253886010362694
South America | 12 | 0.06217616580310881
· Selectivity
总结:
与“亚洲”对应的最常见频率值为0.227979。因此,在该估计中使用0.227979作为选择性。
对于列值可选项很高的情况,就不能使用MCV,则使用目标列的直方图界限值来估计成本。
· histogram_bounds
是一个值列表,用于将列的值分成大致相等的总体组
· Buckets and histogram_bounds

testdb=# SELECT histogram_bounds
FROM pg_stats
WHERE tablename = 'tbl' AND attname = 'data';
默认情况下,直方图界限被划分为100个桶。上面查询说明了这个例子中的桶和相应的直方图范围。bucket从0开始编号,每个bucket存储(大约)相同数量的元组。直方图界限的值是相应存储桶的界限。例如,直方图上界的第0个值是1,这意味着它是存储在bucket_0中的元组的最小值;第1个值是100,这是存储在bucket_1中的元组的最小值,依此类推。
· Selectivity
WHERE data<240计算选择性
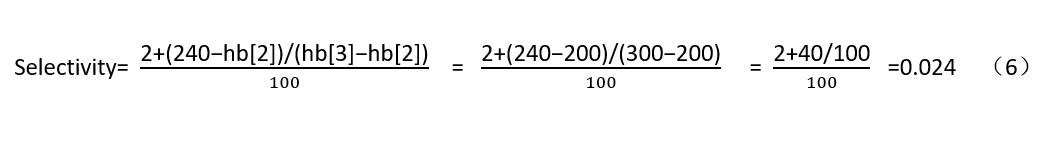
· IndexScan成本估算
前三个成本(即索引cpu成本,表cpu成本和索引IO成本)计算公式:

根据(1,3,4,6)索引cpu成本、表cpu成本和索引IO成本计算结果:
‘index cpu cost’=0.024×10000×(0.005+0.0025)=1.8, (7)
‘table cpu cost’=0.024×10000×0.01=2.4, (8)
‘index IO cost’=ceil(0.024×30)×4.0=4.0. (9)
· IndexScan成本估算
table IO cost计算公式:

· IndexScan成本估算
max_IO_cost计算公式与结果:

min_IO_cost计算公式与结果:

· indexCorrelation
indexCorrelation=1.0 (12)
根据(10,11,12)得出:
‘table IO cost’=180.0+〖1.0〗^2×(5.0?180.0)=5.0 (13)
根据(7,8,9,13)得出索引访问总成本:
‘run cost’=(1.8+2.4)+(4.0+5.0)=13.2 (14)
· 列的indexCorrelation查询
testdb=# \d tbl_corr
Table "public.tbl_corr"
Column | Type | Modifiers
----------+---------+-----------
col | text |
col_asc | integer |
col_desc | integer |
col_rand | integer |
data | text |
Indexes:
"tbl_corr_asc_idx" btree (col_asc)
"tbl_corr_desc_idx" btree (col_desc)
"tbl_corr_rand_idx" btree (col_rand)
testdb=# select * from tbl_corr;
col | col_asc | col_desc | col_rand | data
----------+---------+----------+----------+------
Tuple_1 | 1 | 12 | 3 |
Tuple_2 | 2 | 11 | 8 |
Tuple_3 | 3 | 10 | 5 |
Tuple_4 | 4 | 9 | 9 |
Tuple_5 | 5 | 8 | 7 |
Tuple_6 | 6 | 7 | 2 |
Tuple_7 | 7 | 6 | 10 |
Tuple_8 | 8 | 5 | 11 |
Tuple_9 | 9 | 4 | 4 |
Tuple_10 | 10 | 3 | 1 |
Tuple_11 | 11 | 2 | 12 |
Tuple_12 | 12 | 1 | 6 |
(12 rows)
· indexCorrelation与表之间的关系
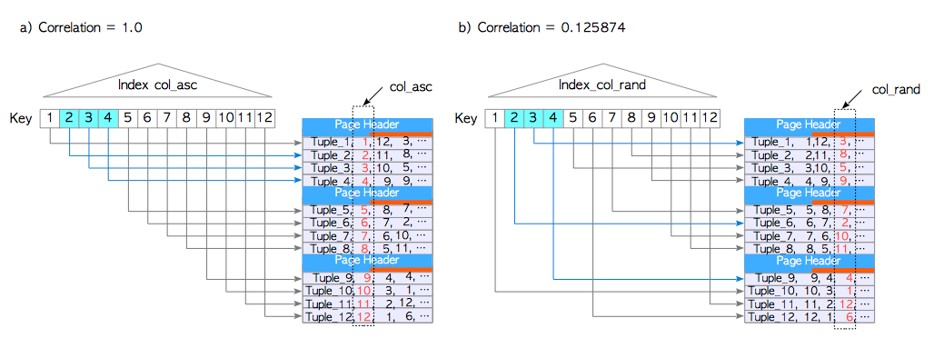
· 列的indexCorrelation查询
testdb=# SELECT tablename,attname, correlation FROM pg_stats
WHERE tablename = 'tbl_corr';
tablename | attname | correlation
-----------+----------+-------------
tbl_corr | col_asc | 1
tbl_corr | col_desc | -1
tbl_corr | col_rand | 0.125874
· 总成本
根据(5,14),得出通过索引访问表的总代价:
(5)--启动成本
(14)--通过索引访问表的成本
‘total cost’=0.285+13.2=13.485 (15)
testdb=# EXPLAIN SELECT id, data FROM tbl WHERE data < 240;
QUERY PLAN
---------------------------------------------------------------------------
Index Scan using tbl_data_idx on tbl (cost=0.29..13.49 rows=240 width=8)
Index Cond: (data < 240)
· seq_page_cost and random_page_cost相关参数配置
HDD硬盘:
seq_page_cost=1.0
random_page_cost=4.0
SSD硬盘:
seq_page_cost=1.0
random_page_cost=1.0
单表查询成本估算之排序
· Sort
成本估算公式:

估算以下查询语句排序成本:
testdb=# SELECT id, data FROM tbl WHERE data < 240 ORDER BY id;
· Sort成本估算

-->> 往期公开课资料,联系CUUG客服领取
以上就是【PostgreSQL从小白到专家】第29讲 -执行计划与成本估算 的内容,欢迎进群一起探讨交流
钉钉交流群:35822460,钉钉群专门有视频讲解